
GIScience News Blog
-
Mapping Progress in Real Time: Highlights from GeoNight 2024 Mapathon with HeiGIT and Mannheimer Mapathons
During GeoNight 2024, HeiGIT partnered with Mannheimer Mapathons to host a mapathon together. Mapathons are events where volunteers come together to map crucial features like roads, buildings or waterways on OpenStreetMap, often in response to specific needs or crises, such as post-earthquake or post-flood scenarios. We were privileged to connect with volunteers from OSM Ghana, gaining insight into…
-
Call for contributions!
Excited to announce the CALL FOR CONTRIBUTIONS! Are you passionate about mapping with communities? Join us at the “Mapping with communities: Contemporary approaches and challenges” workshop at AGILE 2024 conference on June 04. Share your experiences, methodologies, and digital innovations in engaging communities with geospatial data. Submit your extended abstract by May 20 to mappingwithcomm@glasgow.ac.uk.
-
GeoNight Mapathon on April 12th
Our next Mapathon is just around the corner, and this time, we’re joining forces with OpenStreetMap Ghana to improve coverage and to help disaster risk assessment.Join us and be a part of the GeoNight 2024 to celebrate geography together in all its forms and facets! Everyone is welcome and no previous knowledge is needed!Do bring your laptop and preferably…
-
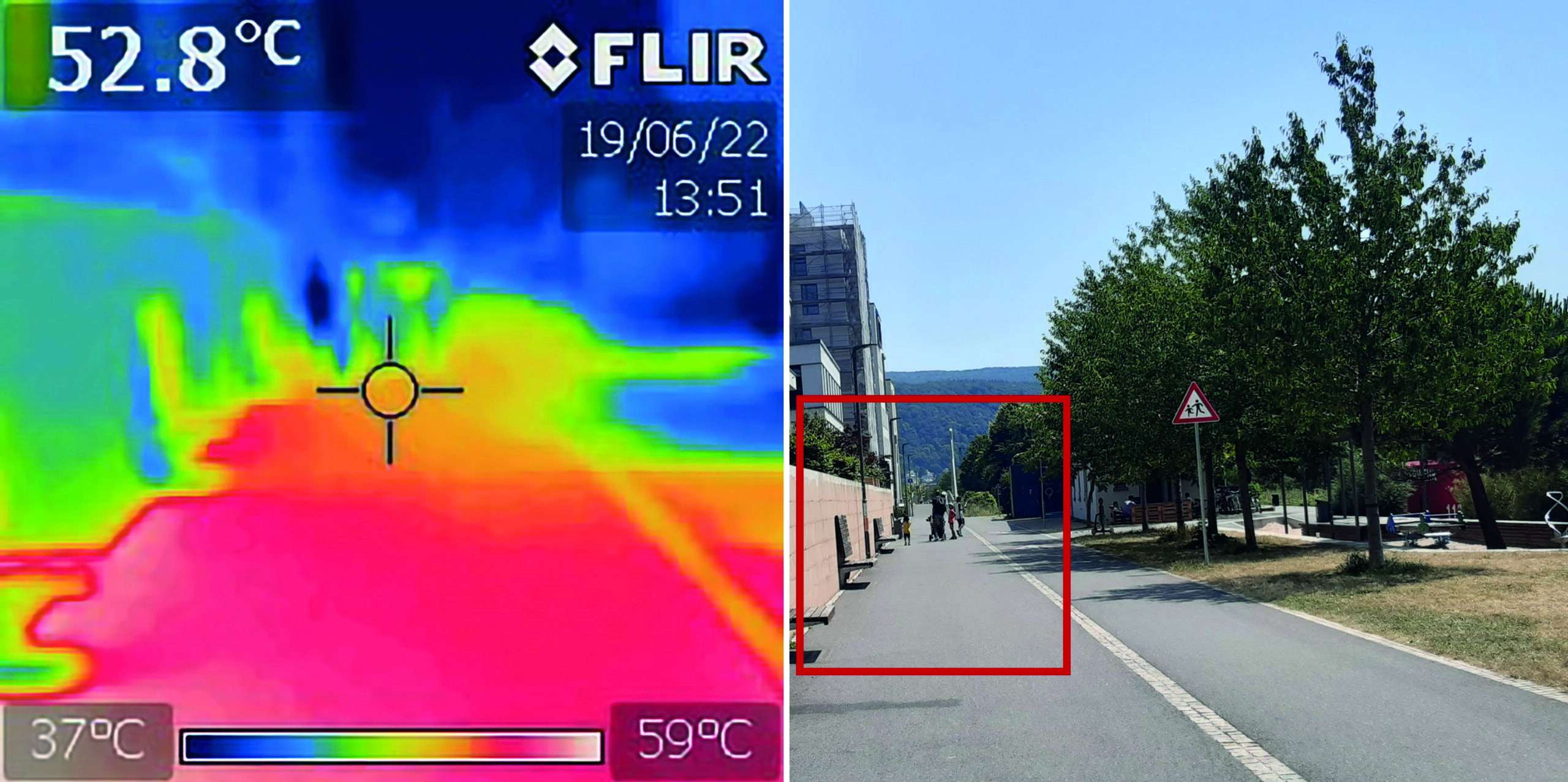
“How to assess the needs of vulnerable population groups towards heat-sensitive routing?”
The research team of the transdisciplinary project HEAL (Heat Adaptation for Vulnerable Population Groups), focusing on providing heat adaptation measures for vulnerable groups in Heidelberg, has published a research paper titled “How to assess the needs of vulnerable population groups towards heat-sensitive routing? An evidence-based and practical approach to reducing urban heat stress”. The paper…
-
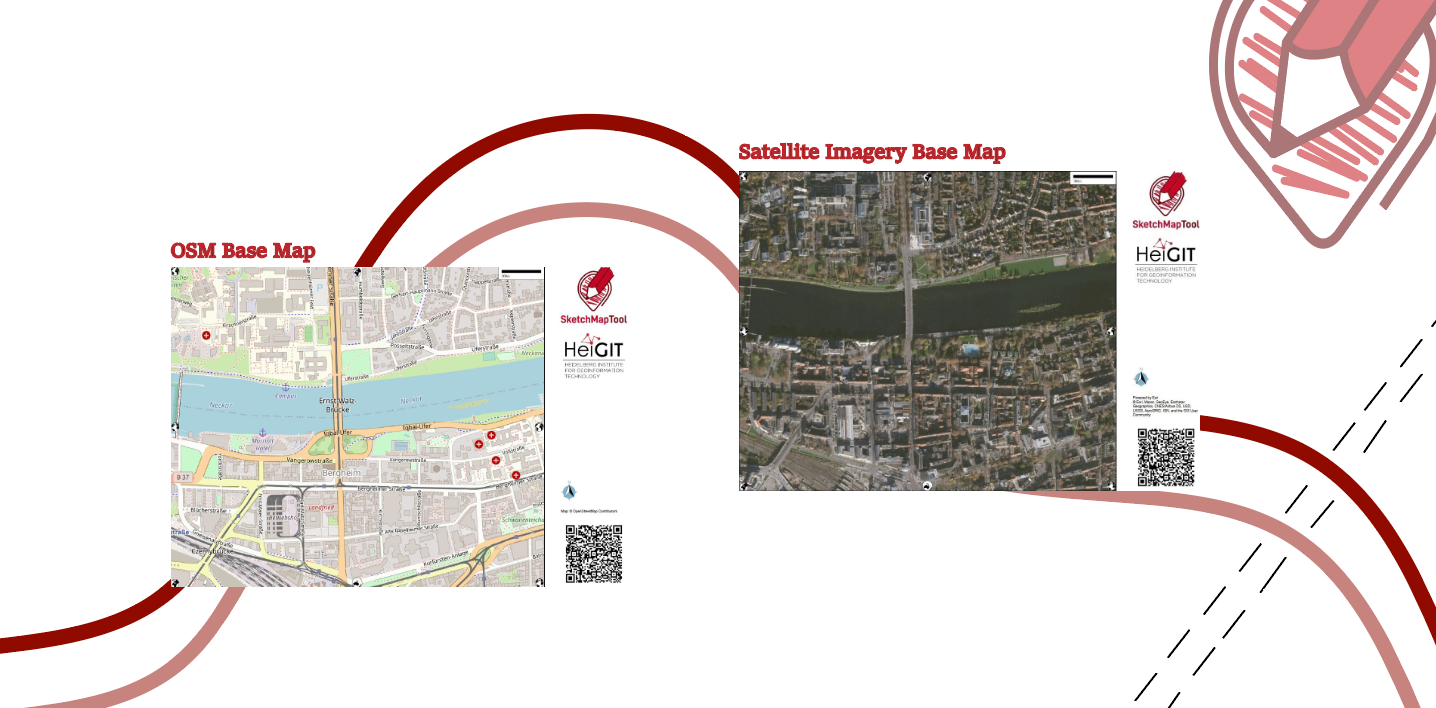
Unveiling the Sketch Map Tool 2.0: A Comprehensive Overview of New Features and Training Opportunities
The HeiGIT gGmbH (Heidelberg Institute for Geoinformation Technology) team has just released a version 2.0 of the Sketch Map Tool, a low-tech solution for participatory sketch mapping through offline data collection, digitization and georeferencing of local spatial knowledge. Thanks to continuous support from the German Red Cross and financial support by the German Federal Foreign Office, the HeiGIT tool has undergone significant enhancements. These updates introduce new features aimed…
-

HeiGIT at FOSSGIS 2024
We’re proud to share our recent conference experience with you! Our HeiGIT Product Owners for Big Data and Smart Mobility, Benjamin Herfort and Julian Psotta, had the privilege of attending the FOSSGIS 2024 conference, where they contributed valuable insights and expertise. The results of an exciting six years of joint work and shared projects between HeiGIT and the Federal Agency for Cartography…
-
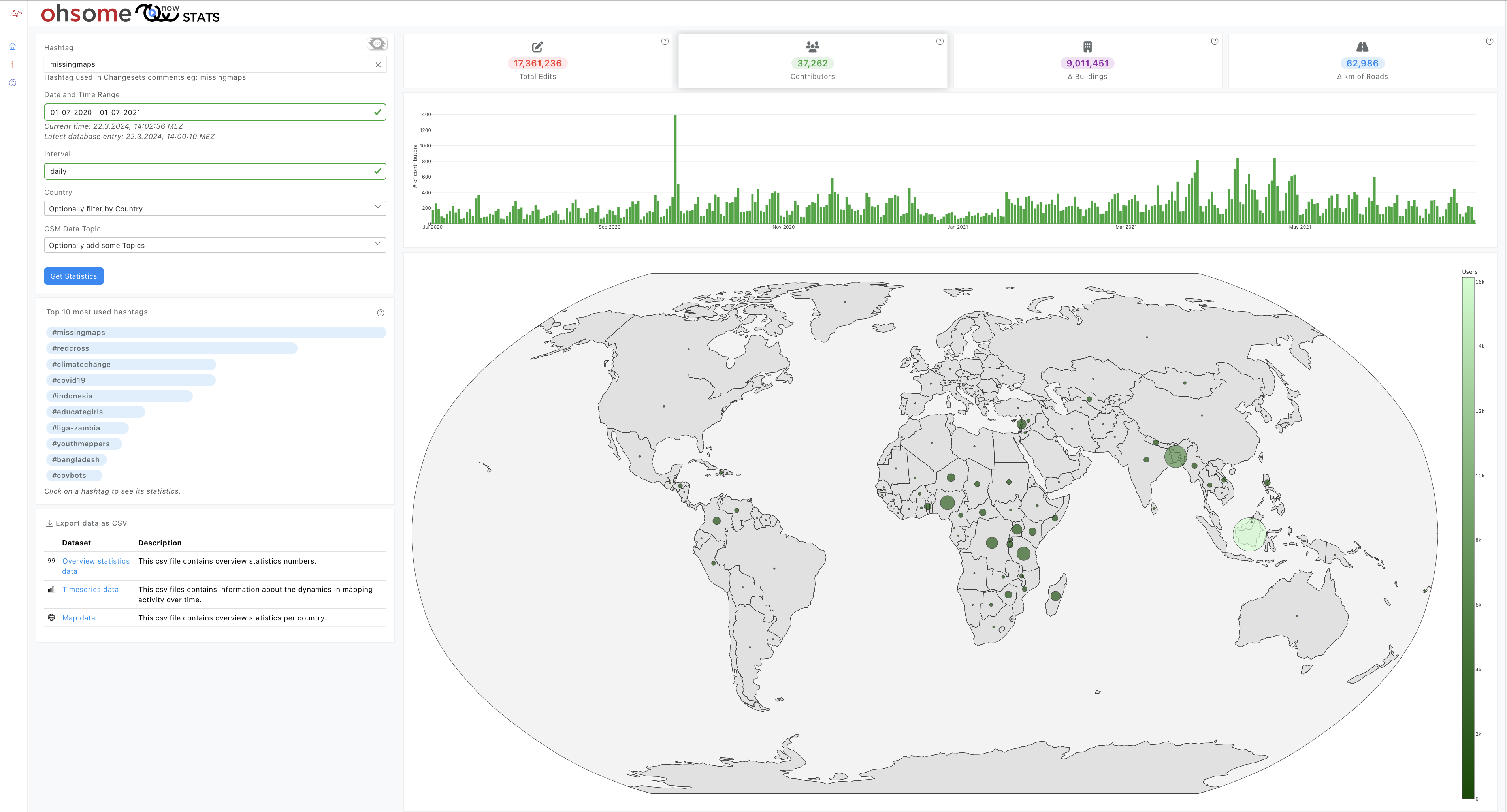
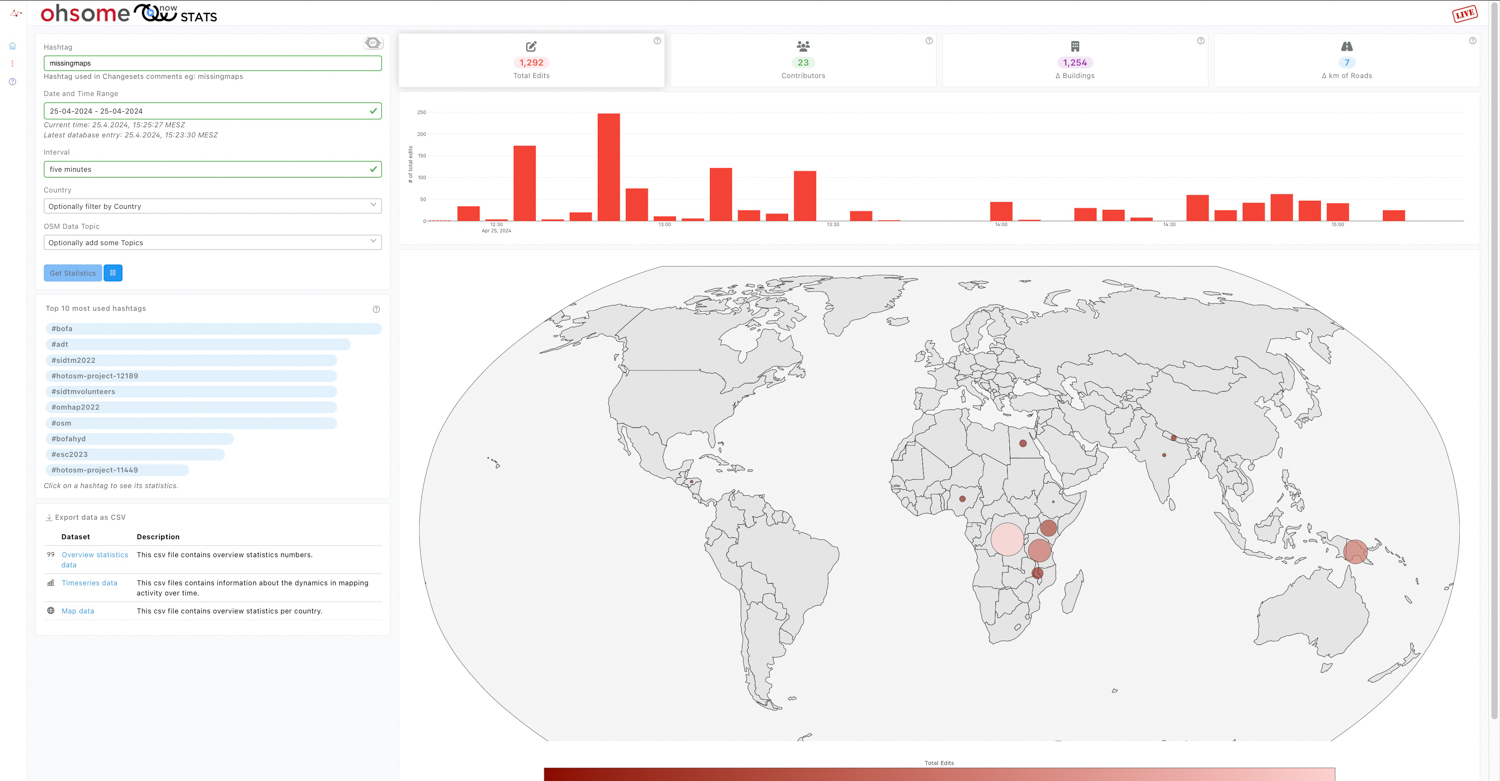
Introducing ohsomeNow stats v1.0
OhsomeNow stats makes it possible to monitor contributions to OpenStreetMap (OSM) in real time. We developed this new dashboard as part of our long-term cooperation with the Humanitarian OpenStreetMap Team (HOT), an international organization dedicated to humanitarian action and community development through open mapping. This dashboard has replaced the Missing Maps Leaderboard with a comprehensive overview…
-
Introducing openrouteservice version 8.0 — A dedication to Wilfried Juling
We’re thrilled to announce the release of openrouteservice (ors) version 8.0, designated “Wilfried”, as a tribute to Prof. Dr. Wilfried Juling, whose steady support and advice fundamentally shaped the growth and success of HeiGIT since its beginning. With countless hours and dedication poured into development and innovation, we’re excited to present a rich set of…
-

Chasing Permafrost: Insights from the Aklavik Expedition
In 2022, we embarked on an insightful expedition to Aklavik, Canada, in collaboration with our partners, the Alfred Wegener Institute (AWI) Helmholtz Center for Polar and Marine Research and the German Aerospace Center (DLR). This joint effort within the UndercoverEinAgenten project aimed to study the extent and velocity of permafrost thawing, a crucial aspect of…
-

Call for Applications – Robert and Christine Danziger Scholarship 2024
The Robert and Christine Danziger Scholarship application window is open until August 31st, 2024, offering a unique opportunity for doctoral candidates from Africa, particularly Ghana or West and Central Africa. The scholarship designed for those pursuing a doctorate at Heidelberg University in the fields of geography (with a focus on geoinformatics) or political science and…
-
Job Opening: Head of Administration (f/m/d)
Are you interested in applying your experience and knowledge to support science-related, non-profit organizations for the betterment of society and the environment? If so, we have a compelling and fitting position for you! HeiGIT gGmbH is a research-oriented, non-profit company that has set itself the goal of improving the transfer of knowledge and technology from…
-
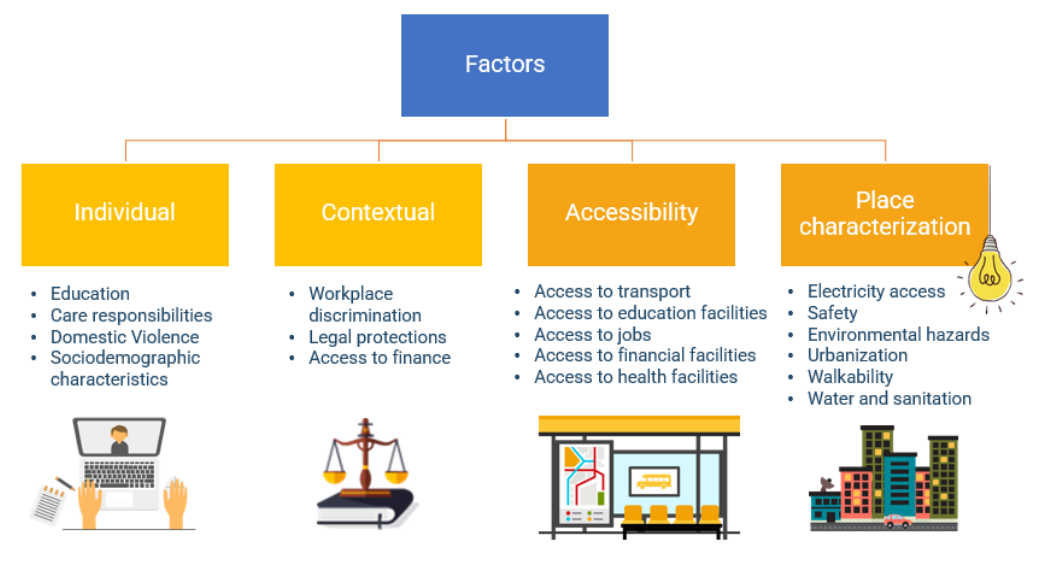
Empowering Change: OpenRouteService in Geospatial Initiatives for Women’s Economic Empowerment and Sustainable Development
The use of open-source geospatial data, exemplified by services like openrouteservice (ORS), proves to be beneficial for both academic research and use case studies. Witnessing our technologies applied in unanticipated ways showcases their potential to meet the evolving needs of various sectors while contributing positively to both society and the environment. One exemplary application is…
3D 3DGEO Big Spatial Data CAP4Access Citizen Science Climate Change Conference crisis mapping Crowdsourcing data quality deep learning disaster DisasterMapping GIScience heigit HELIOS HOT humanitarian humanitarian mapping Humanitarian OpenStreetMap team intrinsic quality analysis landuse laser scanning Lidar machine-learning Mapathon MapSwipe Missing Maps MissingMaps ohsome ohsome example Open data openrouteservice OpenStreetMap OSM OSM History Analytics Public Health quality analysis remote sensing routing social media spatial analysis Teaching VGI Workshop