
GIScience News Blog
-
Joint International Tropical Medicine Meeting 2023
GIScience member and PhD candidate Steffen Knoblauch was invited as a speaker at the Joint Internationl Tropical Medicine Meeting (JITMM) 2023. The conference’s focal topic was “Achieving the SDGs: Human and AI-driven Solutions for Tropical Medicine in a Changing world” and it was hosted by the faculaty of Tropical Medicine, Mahidol University and co-organized by…
-

Somaliland GIS Training
Since 2022, HeiGIT is providing technical support to the Somali Red Crescent Society (SRCS) in Somalia. The objective was the development of an Early Action Protocol (EAP) for droughts in Somalia, a plan developed by RCRC National Societies that outlines early actions to be taken when a specific hazard is forecasted to impact communities. In…
-
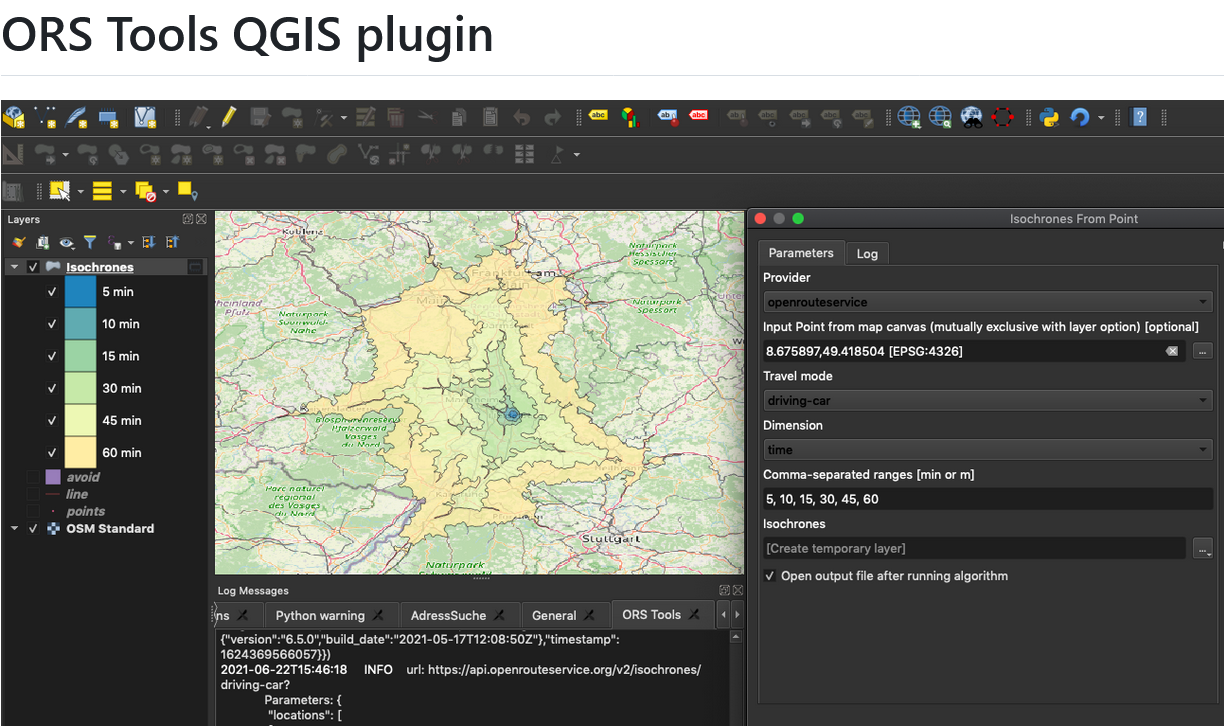
ORS Tools QGIS Plugin Release v1.7.0
Just in time for the new year, the openrouteservice team proudly announces the release of v1.7.0 of the ORS Tools QGIS plugin! Quite a lot has happened. First, the GUI was reworked: Next, there are a few other things that happened: Check out the changelog if you’re interested in all the in-depth details. Feedback and…
-
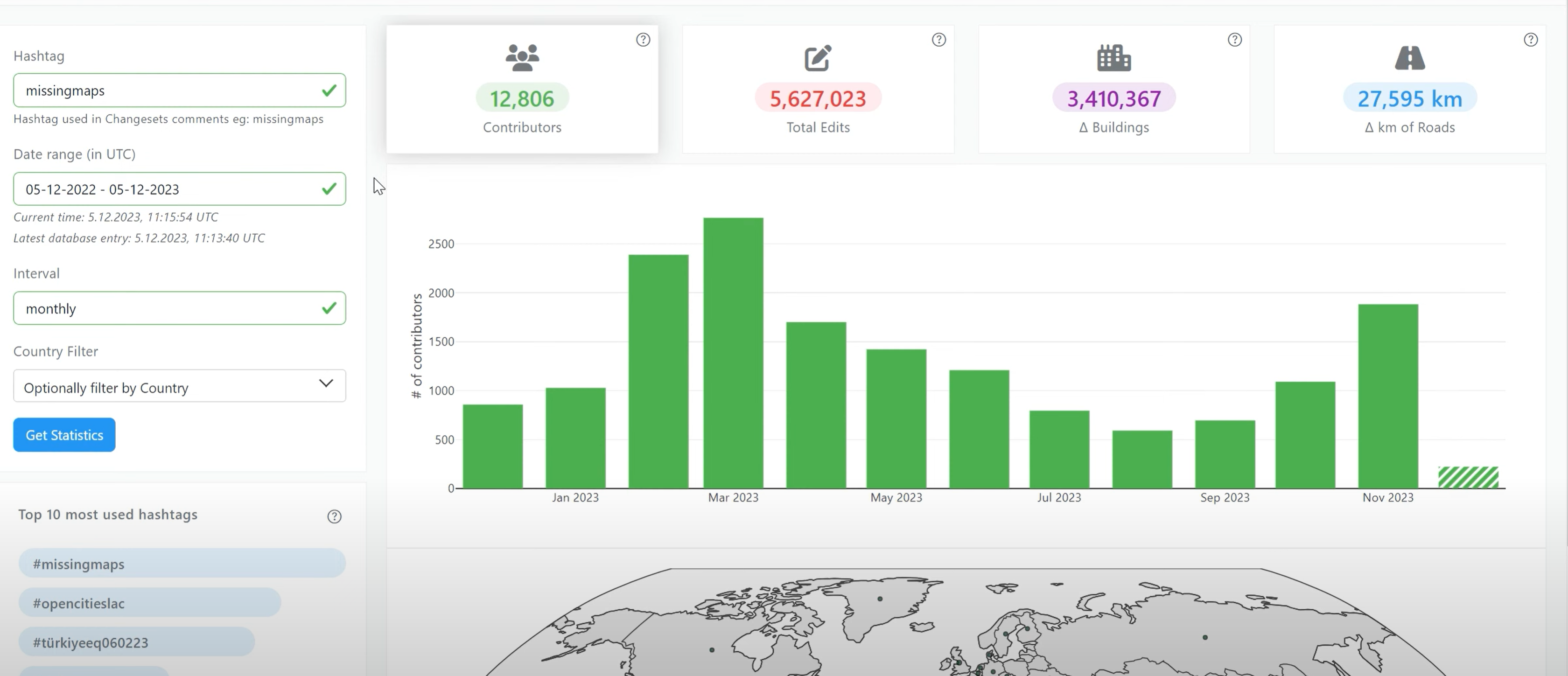
Introducing OhsomeNowStats
OhsomeNowStats allows users to take a look at the mapping activity in OpenStreetMap. This is especially useful for humanitarian organizations and mapathon organizers, because OhsomeNowStats data is updated every 5-10 minutes. Using this tool, user-engagement can be tracked in near real time and used to motivate participants and volunteers alike! By selecting a time range,…
-
IT Systems Engineer (m/f/d, up to 100%)
Are you passionate about automation, monitoring and the development of innovative IT infrastructures? Are you an enthusiast for open source software? And would you like to work with developers and researchers to further develop software in the field of geoinformatics from an operational perspective? We need your expertise to professionalize and fortify our IT services…
-

Looking back at SOTM Africa and Missing Maps Gathering
The recently concluded State of the Map Africa 2023, hosted in Yaoundé, Cameroon, marked the fourth edition of this regional OpenStreetMap (OSM) conference. The State of the Map was a great opportunity to get to know the people who are at the center of building open mapping communities in African countries. For the first time…
-

The Year 2023 at HeiGIT
As 2023 is coming to an end, we would like to take the opportunity to look back at this eventful year and appreciate the advance that HeiGIT has made towards its goal of enabling and improving the transfer of knowledge and technology. Thanks to the collective efforts of each team member and the GIScience community,…
-
HeiGIT-Team Wins “Open Source Software for Sustainable Development Goals (OSS4SDG)” Hackathon
The HeiGIT team recently secured the top position in the third edition of the Open Source Software for Sustainable Development Goals (OSS4SDG) hackathon. These hackathons are based on the 17 Sustainable Development Goals (SDGs) of the UN. The participants were tasked to take on one of seven challenges, each with the goal to develop and…
-
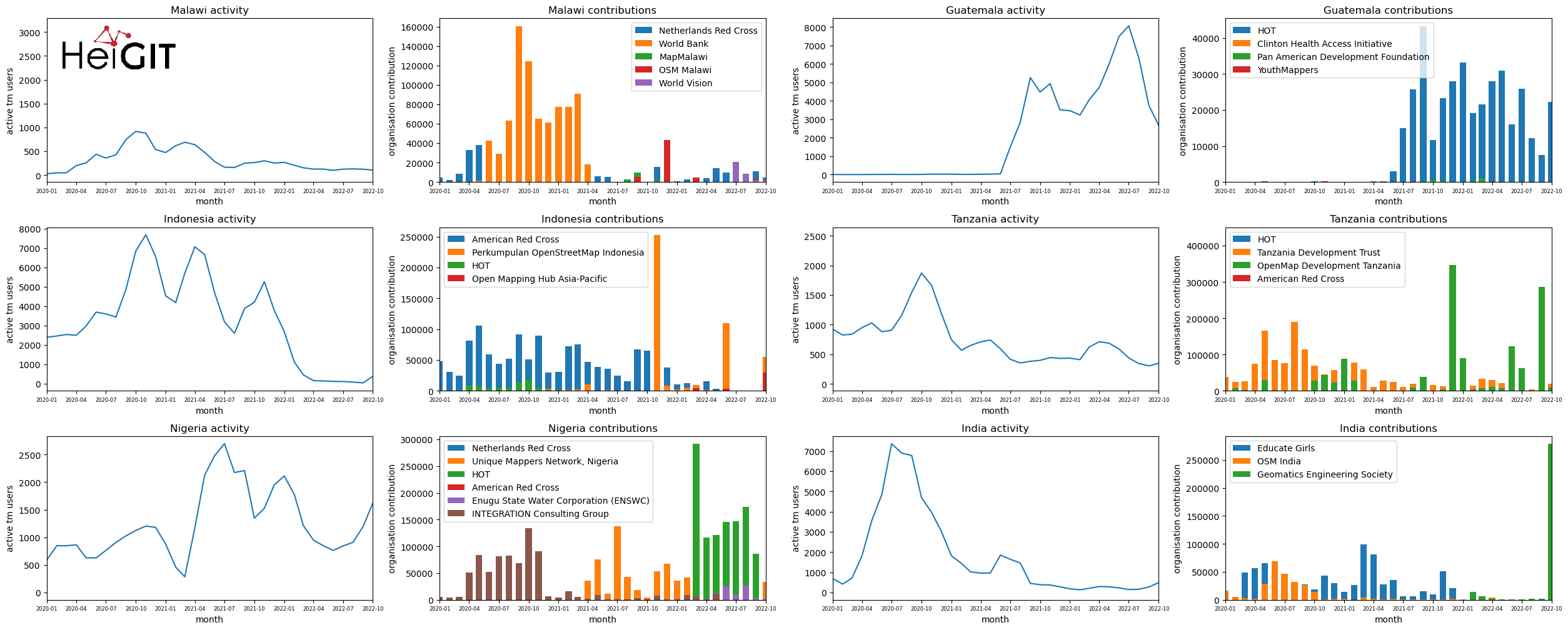
Analysis of Humanitarian OSM Stats: User activity through HOT-TM and contributing organizations
Introduction In this blogpost we are taking a look at humanitarian mapping through the Tasking Manager (HOT-TM) that is operated by the Humanitarian OpenStreetMap Team (HOT). At HeiGIT we work together with HOT to provide analyses and statistics to further understand mapping activity. Explore the user and mapping stats of all Tasking Manager activites here. Check our blog posts about topics…
-

New paper on the potential of simulated laser scanning and field data to train forest biomass models
In great collaboration with colleagues from Karlsruhe (DE), Vienna (AT), Brno (CZ), Leipzig (DE), Raszyn (PL), and Berlin (DE), we published a paper investigating approaches to improve LiDAR-based biomass models when only limited sample plots with field data are available. The main work was carried out by PhD student Jannika Schäfer (IFGG, Karlsruhe Institute of…
-

DFG Software Grant
Successful proposal: Fostering a community-driven and sustainable HELIOS++ scientific software The 3DGeo Group and the Scientific Software Center (SSC) of Heidelberg University have been successful with their proposal in the DFG call “Research Software – Quality assured and re-usable”, together with two other project proposals at Heidelberg University (see press release). The main objective of…
-

HeiGIT at State of the Map Europe 2023
This year’s State of the Map Europe Conference (SotM EU) took place in Antwerp, Belgium. HeiGIT’s Benjamin Herfort and Jochen Stier visited the conference. SotM is a platform hosting OSM mappers, open-source developers, researchers, GIS professionals, cartographs and many more interested people. The goal is to offer an opportunity for those groups and individuals to…
3D 3DGEO Big Spatial Data CAP4Access Citizen Science Climate Change Conference crisis mapping Crowdsourcing data quality deep learning disaster DisasterMapping GIScience heigit HELIOS HOT humanitarian humanitarian mapping Humanitarian OpenStreetMap team intrinsic quality analysis landuse laser scanning Lidar machine-learning Mapathon MapSwipe Missing Maps MissingMaps ohsome ohsome example Open data openrouteservice OpenStreetMap OSM OSM History Analytics Public Health quality analysis remote sensing routing social media spatial analysis Teaching VGI Workshop